Our approach
How we build something that books jobs while you sleep.
No checklist theater, no black-box vendor. Four phases — discovery, build, launch, iterate — that put the Voxaris Pitch estimator on your domain, wire it to your CRM, and keep it sharp on real homeowner behavior. Here's exactly how we work.
Built for you · live in days · month to month
The work, in order
Discovery → build → launch → iterate.
The same four phases on every engagement. Nothing skipped, nothing hand-waved. You always know which phase you're in and what you get out of it.
- 01
Discovery
We learn your shop before we build anything.
- 02
Build
We build the estimator on your brand, not ours.
- 03
Launch
We go live and point your traffic at it.
- 04
Iterate
We tune it on what homeowners actually do.
Phase by phase
What each phase actually involves.
Every phase names the work we do and what you walk away with. No vague "strategy" line items — concrete deliverables you can point at.
Discovery
We learn your shop before we build anything.
We sit down with how you actually sell — your service area, your roof types, your Good/Better/Best pricing logic, and where leads slip through today. Nothing gets built until the estimator would say what your best rep would say on the phone.
- ✦Your pricing logic, captured the way you'd quote it
- ✦A map of where leads go cold right now
- ✦A scoped build plan you sign off on before we start
Build
We build the estimator on your brand, not ours.
We stand up Voxaris Pitch on your domain, in your colors, under your logo. We connect the satellite measurement to your pricing and wire the booking step straight into your CRM. The work lives on our side — you don't learn new software or change how your team runs.
- ✦White-labeled estimator on your own domain
- ✦Your pricing wired to the satellite measurement
- ✦Booking step connected to your CRM
Launch
We go live and point your traffic at it.
We take the estimator live, test it against real addresses in your market, and point your ads, site, and yard-sign QR codes to it. From the moment it's up, any homeowner can get an instant branded estimate — and the serious ones can book the inspection in the same flow.
- ✦Live, tested estimator in your market
- ✦Your traffic routed to the booking flow
- ✦A pre-measured lead landing in your CRM on every booking
Iterate
We tune it on what homeowners actually do.
Once it's running, we watch how real homeowners use it — where they price, where they book, where they drop. We adjust the flow and the pricing presentation to fit your market. The estimator keeps running while you sleep; we keep sharpening it.
- ✦Ongoing tuning against real homeowner behavior
- ✦Adjustments to flow and pricing presentation
- ✦A standing line to a real person when something needs to change


What we're building toward
Every phase serves one moment.
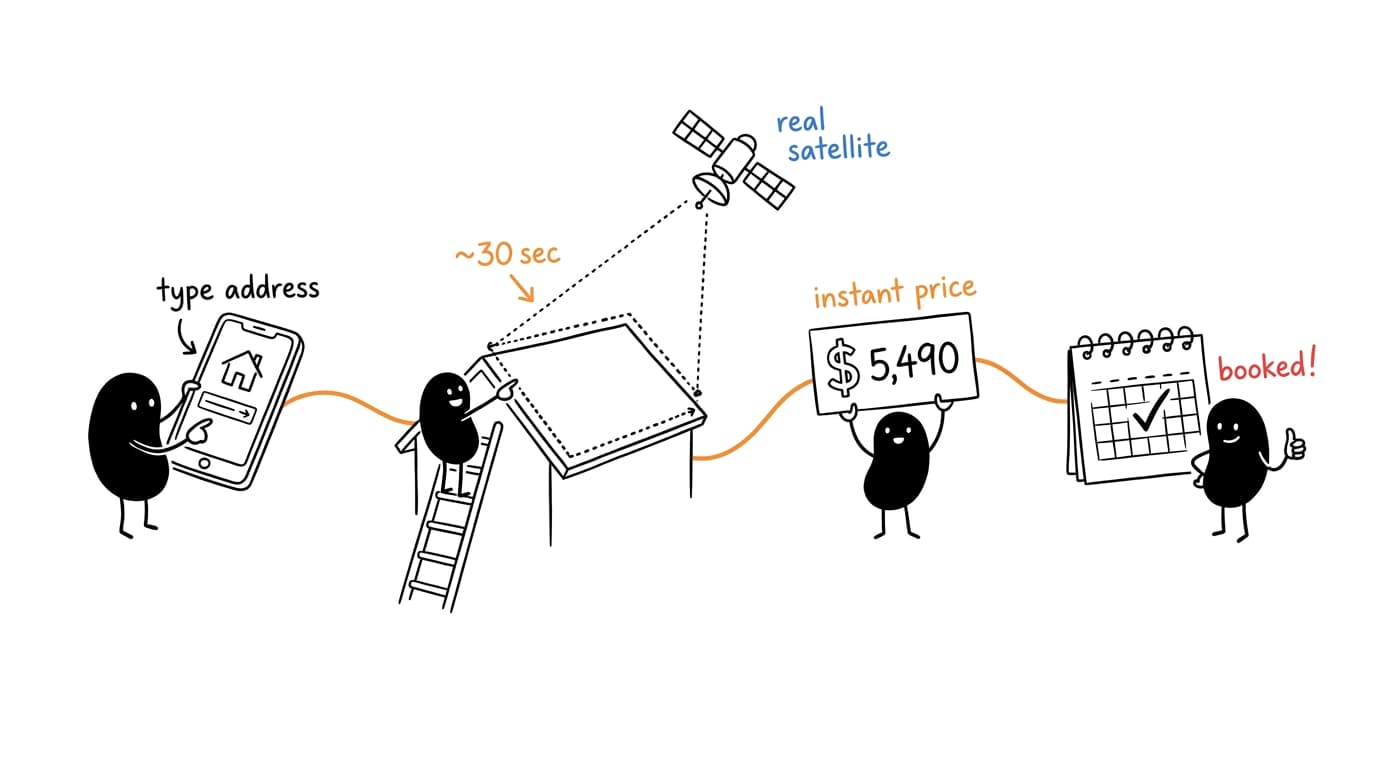
All four phases exist to make this work: a homeowner types an address, the real roof is measured from satellite, and an honest Good/Better/Best range books the inspection — in under 30 seconds, on your brand. Discovery makes the price right. Build makes it yours. Launch turns it on. Iteration keeps it sharp.
See a live measurementHow we make build decisions
The principles under every phase.
Honest by default
The instant estimate is a real Good/Better/Best ballpark built to book the inspection and set expectations — not a final number. Your rep confirms on-site. We never pretend an instant estimate is the last word, and we don't ship numbers we can't stand behind.
Your brand, start to finish
Everything we build is white-labeled. Your logo, your domain, your colors. Homeowners see your company the whole way through and never see Voxaris. You own the customer and the relationship.
Zero new workload
You don't measure roofs, learn new software, or change how your team works. The build is on us. You show up to inspections that booked themselves.
Start with discovery
See phase one on your own address.
Bring any address — yours, a customer's, a job site. We'll show you the estimator measuring and pricing it live, on your branding, and walk you through exactly how the build would run for your shop. Month to month, cancel anytime.
- ✦A real estimate on your own address
- ✦Built and branded as your company
- ✦Live in days
A clear process. A real person on the other end.
See how the four phases would run for your shop — start with the estimator on a roof you know.